The foundations of Data Predicitve Control (DPC) for cyber-physical systems
Control-oriented models are required for predictive control of intelligent energy and industrial systems. Building first principles-based models is cost and time prohibitive. Machine learning models (black-box) on the other hand, are easier to build but are not suitable for control synthesis. With Data Predicitve Control (DPC) we bridge the modeling incompatibility gap between machine learning models and control synthesis by building control-oriented and interpretable regression tree based models.
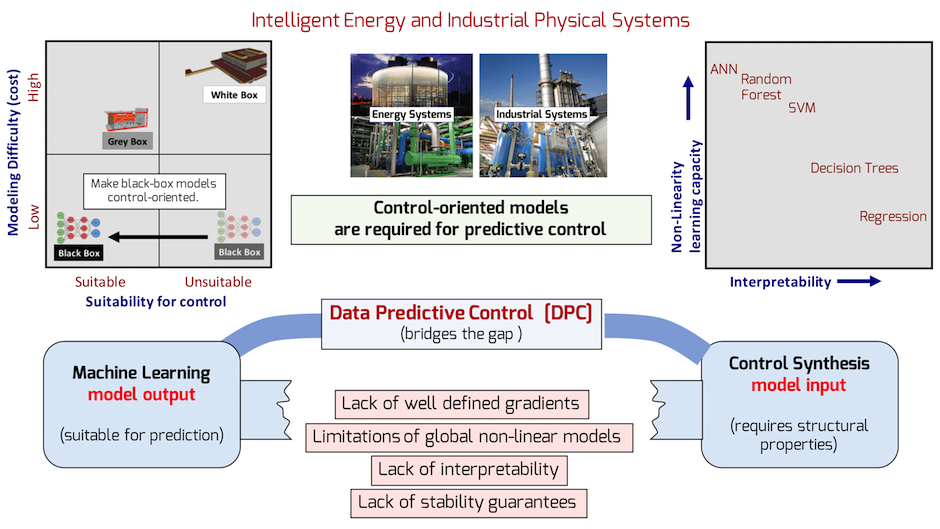
What is data predictive control ?
Control-oriented predictive models of a cyber-physical system’s dynamics are needed for understanding and improving the system operation, especially under uncertainty. We define control-oriented models as dynamical models which are suitable for finite horizon model-based predictive control synthesis.
System identification techniques are usually used to identify parameters of a physics based white-box or grey- box model which attempt to model the system behavior using first principles. The preference for building first principles based models, arises due to the fact that the parameters of these models have a physical meaning and that the model structure is suitable for traditional control synthesis approaches such as model predictive control (MPC).
Until recently, industrial and energy applications of MPC have relied upon linear dynamic models even though most processes are nonlinear. However, these processes operate over the nonlinear range of the system and linear MPC often results in poor performance. To properly control these processes, a nonlinear model is needed in the MPC algorithm. Nonlinear Model Predictive Control (NMPC) has been applied in many applications due to its ability to handle constraints and its useful robustness properties. There are, however, certain drawbacks associated with the NMPC. These include:
- Complexity of implementation on low-memory devices,
- Increased computational burden due to iterative computation of on-line optimal control actions, (especially in the design of nonlinear controllers),
- Reduced computational efficiency when applied to higher-dimensional models, and,
- Difficulty in guaranteeing closed-loop properties of the control scheme.
The key insight of MPC is that an accurate predictive model allows us to optimize control inputs for some cost over both inputs and predicted future outputs. Such a cost function is often easier and more intuitive to design than completely hand-designing a controller. The chief difficulty in MPC lies instead in designing an accurate dynamics model. Building such models is very challenging since most intelligent physical systems are very complex systems to model. The complexity arises due to the interaction between a large number of subsystems and their very different nature with respect to physical dynamics, uncertain behavior, timing, and size.
The major barrier in modeling intelligent physical systems with first principles based approaches, is the user expertise, time, and associated high costs required to develop a mathematical model that accurately reflects reality. This often includes the installation cost of retrofitting the system with additional sensors, costs related to the training of the engineering, commissioning and service personnel to implement model-based control and the cost of the necessary engineering effort required for constructing a model.
The alternative is to use black-box, or completely data-driven modeling approaches, based on machine learning algorithms. The primary advantage of using machine learning methods for the system’s model is that it has the potential to eliminate the time and effort required to build first principles based models. Listening to real-time data, from existing systems and interfaces, is far cheaper than unleashing hoards of on-site engineers to physically measure and model the physical system.
Data predictive control is a framework designed to combine the simplicity of data-driven methods with the predicitve capability of model-based control. Using DPC algorithms, one can synthesise fintie-horizon predicitve control decicions after learning dynamical system models based on hsitorical data.
mbCRT: Model-based control with regression trees
At the core of DPC lies the model based control with regression trees (mbCRT) algorithm. mbCRT allows us to enable finite receding horizon control sythesis using regression tree models.
Our goal is to find data-driven functional models that relates the value of the response variable, say power consumption, \(\hat{Y_{kW}}\) with the values of the predictor variables or features \([X_1, X_2,\cdots, X_m]\) which can include weather data, set-point information and building schedules.
When the data has lots of features, as is the case in large buildings, which interact in complicated, nonlinear ways, assembling a single global model, such as linear or polynomial regression, can be difficult, and lead to poor response predictions.
An approach to non-linear regression is to partition the data space into smaller regions, where the interactions are more manageable.
We then partition the partitions again; this is called recursive partitioning, until finally we get to chunks of the data space which are so tame that we can fit simple models to them.
Therefore, the global model has two parts: the recursive partition, and a simple model for each cell of the partition.
Regression trees is an example of an algorithm which belongs to the class of recursive partitioning algorithms. The seminal algorithm for learning regression trees is CART (Breiman 1994).
Given a forecast of the features \(\hat{X_1}, \hat{X_2},\cdots, \hat{X_m}\) we can predict the response \(\hat{Y}\).
Now consider the case where a subset, \(\mathbb{X}_c \subset \mathbb{X}\) of the set of features/variables \(\mathbb{X}\)'s are manipulated variables \ie we can change their values in order to drive the response \((\hat{Y})\) towards a certain value.
In the case of buildings, the set of variables can be separated into disturbances (or non-manipulated) variables like outside air temperature, humidity, wind etc. while the controllable (or manipulated) variables would be the temperature and lighting set-points within the building.
Our goal is to modify the regression trees and make them suitable for synthesizing the optimal values of the control variables in real-time.
Separation of variables
The key idea in enabling control synthesis for regression trees is in the separation of features/variables into manipulated and non-manipulated features. Let \(\mathbb{X}_c \subset \mathbb{X}\) denote the set of manipulated variables and \(\mathbb{X}_d \subset \mathbb{X}\) denote the set of disturbances/ non-manipulated variables such that \(\mathbb{X}_c \cup \mathbb{X}_d \equiv \mathbb{X}\). Using this separation of variables we build upon the idea of simple model based regression trees to model based control with regression trees (mbCRT)